Na Du, hat’s Dich erwischt?
Offensichtlich, denn sonst hättest Du den Artikel nicht gegooglet. Vorab, mein Beileid! Es ist aber wieder hinzubekommen! Es gibt bestimmte Umstände, in denen ein CSV (Cluster Shared Volume) nicht mehr lesbar ist. Diese Umstände sind dem einen oder dem anderen mehr oder weniger bekannt. Es können hardwarebedingte Ursachen sein, hier z.B. Enumeration der LUN’s nach einem Festplattenausfall auf der SAN-Seite, falsch eingestellte HBA’s – dazu später noch ein paar Screenshots oder die verkehrte Reservierungseinstellung eines SAN’s, Virenscanner, falsche Bedienung oder veraltete Storporttreiber. Wie schaut es bei Dir jetzt aus? Offensichtlich wie folgt:
Fehlerbeschreibung:
Alle Maschinen, welche sich auf einem CSV befunden haben sind tot. Ein Verschieben ist unmöglich, da Du erkennst, dass Du im Clustermanager unter //Speicher zwar die konfigurierte Festplatte hast, allerdings nicht das dazugehörige Volume: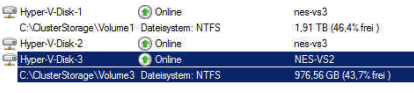
Anschließend gehst Du die Clusterereignisse durch, und entdeckst einen solchen Eintrag:

In diesem Fall fehlt Dir „der Inhalt“ der in diesem Beispiel gezeigten „Hyper-V-Disk-2“, welche sich nicht mehr auf dem Clusterknoten „nes-vs3“ befindet. Schaust Du dann auf dem entsprechenden Clusterknoten in die Datenträgerverwaltung, siehst Du ein Volume, allerdings leer und ohne MBR:

Das dürfte so in etwa Dein Szenario sein. Doch wie ist es dazu gekommen? Es gibt viele unterschiedliche Ursachen, die meist entweder mit dem Verlust von FC-Verbindungen zusammen hängen oder auch einher mit Fehlkonfigurationen des Backups, insbesondere DPM gehen. Weiterehin – so stellte ich fest – kann dieser Fehler des Verlustes eines Volumes auch vorkommen, wenn z.B. der Clusterüberprüfungsassistent durchgeführt wird, und dass während sich der DPM ein Volume geschnappt hat und/oder ein Volume im umgeleiteten Zustand ist. Alle Resultate haben gemein, dass die Seriennummer des Volumes nicht mehr zum eigentlich erwarteten passt. Das Cluster kennt den Datenträger sprichwörtlich nicht mehr, siehe in meinem Screenshot Datenträger 4.
Verhinderung von CSV-Verlusten aufgrund von Fehlkonfigurationnen:
FC/SAN
Das schlimmste jedoch ist eine falsche Einstellung der HBA’s, siehe hierzu z.B. mein Beispiel für die richtige Einstellung mit HBAnywhere anhand einer DX80/FSC. Erst wenn HBAnywhere richtig konfiguriert wird, kann Überlast an einer (wie in diesem Beispiel verwendet) DX80 vermieden werden, siehe dazu die in Rot markierten Änderungen:
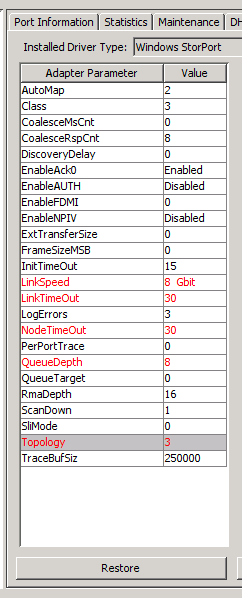
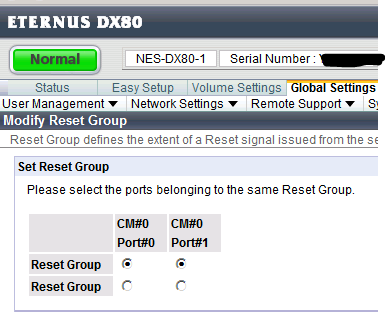
Insbesondere Queue Depth (siehe oben) und der Link Speed ist hier eine entscheidende Größe. Sollte Queue Depth nicht richtig konfiguriert sein, so kann es genauso zum Verlust der SAN-Verbindung kommen, wie z.B. eine nicht festgestzte Verbindungsgeschwindigkeit. „Haben Sie schon einmal einen normalen Switch gesehen, bei dem Autosensing zu 100% funktioniert?“ fragte mich dazu der Support von Fujitsu – Also beim HBA auch unbedingt die Verbindungsgeschwindigkeit festsetzen. Sicherlich hast Du andere Hardware und deswegen auch andere Grundeinstellungen zu beachten. Dazu kommt dann auch noch die richtige Konfiguration des Resetsignals, wie unten im Screenshot gezeigt, ist bei Dir sicherlich anders bedingt, nur achten solltest Du darauf.
Treiber/Virenschutz
Du solltest darauf achten, sofern Du einen Virenscanner einsetzt, dass Du den KB-Artikel 250355 von Microsoft gelesen und umgesetzt hast. Ich würde generell von der Verwendung eines Virenscanners auf dem Clusternodes abraten.
Weiterhin kam es in der Vergangenheit häufiger zu Updates von Microsoft bei den Storport-Treibern. Insbesondere solltest Du darauf achten, dass Du bei FC-Verbindungen mindestens KB2769701 und KB2780444 in entsprechender Reihenfolge installiert hast.
Lösung/Reparatur
Es gibt im Netz verschiedene Ansätze, allerdings muss es nicht heißen, dass dieser Ansatz bei Dir funktioniert. Du solltest das LUN vorher gesichert haben und Dich in den einschlägigen Microsoft Artikeln und Foren umsehen. In meinem Fall besteht das Cluster aus drei Nodes und drei Clustervolumes, sowie mindestens einem externen Domänencontroller. Du solltest die Clusterquorumkonfiguration temporär umstellen, und zwar wie folgt:
Jetzt hast Du die Möglichkeit, die verbliebenen, wichtigsten HyperV Maschinen auf ein Node zu migrieren. Anschließend schiebst Du alle Speichervolumes an das gleiche letzte Node, was Du online halten möchtest (genügend Hauptspeicher vorausgesetzt):

Und fährst alle anderen Clusternodes physikalisch herunter – Strom aus. Alle Nodes bis auf eines dürfen nicht mehr mit dem SAN sprechen. Ein einzelnes Clusternode sollte den Cluster jetzt noch hochhalten können und die für die Anwender noch verfügbaren Maschinen können weiterlaufen. Der Clusterdienst muss in meinem Fall nicht heruntergefahren werden, es gibt hierzu widersprüchliche Äußerungen im Netz und in den KB-Artikeln.
- Anschließend initialisierst Du das Volume in der Datenträgerverwaltung des letzten Nodes, welches online ist. Der Datenträger sollte so initialisiert werden, wie Du ihn zuvor hattest laufen lassen. Formatiert wird er auf gar keinen Fall.
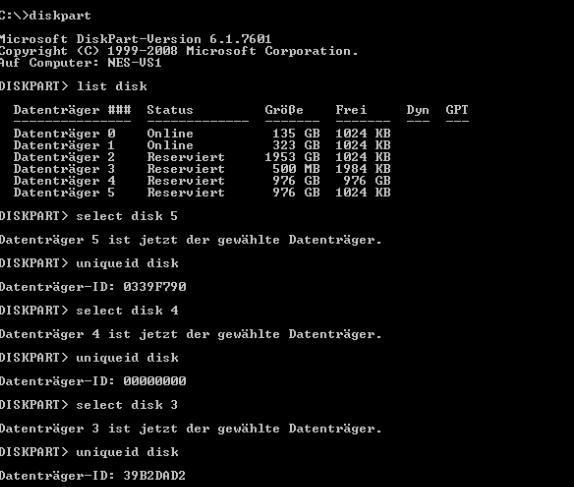
- Danach wählst Du mittels „diskpart.exe“ und select disk „#“ die richtige #, neu initialisierte Festplatte aus
- Dann überprüfst Du mittels uniqueid disk die Seriennummer und schreibst, sofern Du die richtige Disk erwischt hast, die richtige Seriennummer (meine ist 0339F674 – Siehe Screenshot Fehlermeldung aus dem Clustermanager^^) mittels für mein Beispiel gültig“uniqueid disk id=0339F674″ zurück in das Volume.
Zum Schluss hast Du einen leeren Datenträger, bei dem das NTFS fehlt. Mittels einem NTFS Recoverytool kannst Du dann die Disk zurückholen, in meinem Fall habe ich das mit einem freien, sehr guten Tool von ESEUS (Link) umgesetzt. Es hat in etwa 30-40 Minuten gedauert.